
20
MAY 2019
Civil fraud cases hinge on litigants proving where specific fraudulent activity occurred. Tax returns, sales records, expense reports, or any other large financial data set can be manipulated. In many instances of fraud, the accused party diverts funds or creates transactions, intending to make their fraud appear as ordinary or random entries. More clever fraudsters ensure no values are duplicated or input highly specific dollar and cent amounts. Such ‘random’ numbers, to them, may appear normal, but few understand or replicate the natural distribution of numbers known as Benford’s Law.
A staple of forensic accounting, Benford’s Law is a useful tool for litigants in establishing patterns of fraudulent activity.
Benford’s Law states that, for any data set of numbers, the number 1 will be the leading numeral about 30% of the time, the number 2 will be the leading numeral about 18% of the time, and each subsequent number (3-9) will be a leading number with decreasing frequency. This decreasing frequency of numbers, from 1 though 9, can be represented by a curve that looks like this:
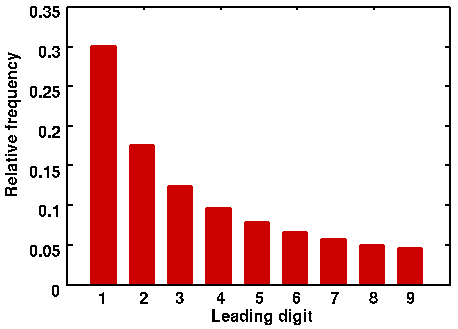
Frequency of each leading digit predicted by Benford’s Law.
For example, according to Benford’s Law, one would expect that more street addresses start with a 1 than a 8 or 3; such hypothesis can be tested and proven. The same pattern holds for any number of phenomenon: country populations, telephone numbers, passengers on a plane, or the volumes of trades. This predicted distribution permeates many aspects of numbers and big data sets. But Benford’s Law is not absolute: it does require larger data sets, and that all the leading digits (1-9) must have a theoretically equal chance of being the leading digit. Benford’s Law, for example, would not apply to a data set where only 4s or 9s are the leading number. Financial data sets do comport with a Benford distribution.
In accounting and financial auditing, Benford’s Law is used to test a data set’s authenticity. False transaction data is typically tampered by changing values or adding additional fake data. The test, therefore, is an early indicator if a data set has been altered or artificially created. Computer generated random numbers will tend to show an equal distribution of leading digits. Even manually created false entries will tend to have some sort of underlying pattern. A person may, for example, input more fake leading digits based on numbers closer to their typing fingers (5 and 6).
An examiner would compare the distribution of leading digits in the data set, and the Benford distrubtion. Then, the examiner would statistically test if the proportion of leading numbers in the data set matches a Benford distribution. The resulting “Z-scores” give a measure of how distorted these distributions are, with higher “Z-scores” implying a more distorted data set, which implies artificially created data.
If a data set violates Benford’s Law, that alone does not prove such transactions numbers fraudulent. But, a violation does give auditors, economists, and fact finders an additional reason to scrutinize individual transactions.